A low agreement between bibliometrics and peer review at the level of individual article indicates that metrics should not replace peer review at the level of individual article.
In 1986, under Margaret Thatcher, the United Kingdom carried out its first national academic research assessment exercise. Since then a growing number of countries have organized similar assessments, which are used for distributing public funding to universities. The evaluation strategies, however, differ: In the UK, for example, the current framework, called REF (Research Excellence Framework), evaluates research product by peer review; other countries, such as Australia, use bibliometric indicators. One of the central questions in the international debate about research evaluation concerns whether scores obtained using bibliometric indicators and peer review tend to converge.
Here, we review one case, which has become very influential in the public discourse: The results of two Italian national research assessments, reported in a recent publication1, seemed to support the thesis of a concordance between the two methods. We already expressed doubts about the results but, now having access to the raw data, we were able to replicate the analysis and prove without question that the concordance between peer review and bibliometrics is lower than weak. In addition, the anomalous high concordance found in the field of economics and statistics in the first attempt was due to an inappropriate experimental protocol adopted exclusively in this field, as decided by the group of economists in charge of the evaluation.
But the implications of our study are broader and caution against the use of massive research assessments to distribute funding.
The study
Bibliometric indicators are defended because of their lower costs, and of their apparent ‘objectivity,’ while peer review is usually defended by stating that reading a paper is the best way to evaluate it. Nevertheless, detractors consider peer review not only the costliest alternative, but also prone to ‘subjective’ biases of the evaluators. There is a consensus, however, that the main drawback of the use of bibliometric indicators is that they produce poor results when applied to humanities and social sciences. Hence, supporters of the massive research assessment approach are very interested in the possibility of performing it by evaluating research products in part by bibliometrics and in part by peer review.
The Italian case is often cited as the main evidence supporting the combined use of bibliometrics and peer review as evaluation techniques in a same research assessment. The Italian governmental agency for research evaluation (ANVUR) adopted a “dual system of evaluation” in its research assessments (VQR 2004-2010; VQR 2011-2014). For science, technology, engineering, and mathematics ANVUR used preferentially bibliometric indicators for evaluating articles in the research assessment exercises. When bibliometric rating was inconclusive, ANVUR asked a pair of reviewers to evaluate the article: indeed, for these articles peer-review evaluation replaced bibliometrics. For economics and statistics, articles were evaluated according to the ranking of journals or alternatively, if the journal was not ranked, by peer review. Social sciences and humanities were evaluated by peer review only. Bibliometric and peer reviewer ratings were then summed up for computing the aggregate score of research fields, departments, and institutions.
If bibliometrics and peer review generated systematically different scores, the use of the “dual system of evaluation” might have introduced major biases in the results of the research assessments. A high level of agreement is therefore a necessary condition for the robustness of research assessment results.
To validate the use of the dual system of evaluation, ANVUR carried out two experiments one for each research assessment. They were based on stratified random samples of articles, which were classified both by bibliometrics and by peer review. Subsequently, concordance measures were computed between the ratings resulting from the two evaluation techniques. Results of the experiments were presented in research reports and in articles authored by different authors as indicating “a more than adequate concordance” or a “fundamental agreement” between peer review and bibliometrics. This is interpreted as supporting the use of the dual system of evaluation and, more in general, as indicating that the two techniques of evaluation are close substitutes.
In a recent paper, thanks to the decision of ANVUR to give us the raw data, we have reexamined in full the two experiments by adopting the same concordance measure used by ANVUR (the weighted Cohen’s kappa coefficient). In order to cast the experiments in the appropriate inferential setting, the design-based estimation of the Cohen’s kappa coefficient and the corresponding confidence interval were developed and adopted for computing the concordance between bibliometrics and peer review. Three suitable alternative estimates of Cohen’s kappa were computed. One of the estimates is the correct version of the Cohen’s kappa adopted by ANVUR.
As for the first experiment for the VQR 2004-2010, the point and interval estimates of the weighted Cohen’s kappas indicate a concordance degree generally lower than 0.4, that can be considered at most weak, for the aggregate population and for each scientific area. The results are drawn in Figure 1. In the second experiment for the VQR 2011-2014, the degree of concordance between bibliometrics and peer review is generally even lower than in the first experiment, see Figure 2.
https://journals.plos.org/plosone/article/figure?id=10.1371/journal.pone.0242520.g003
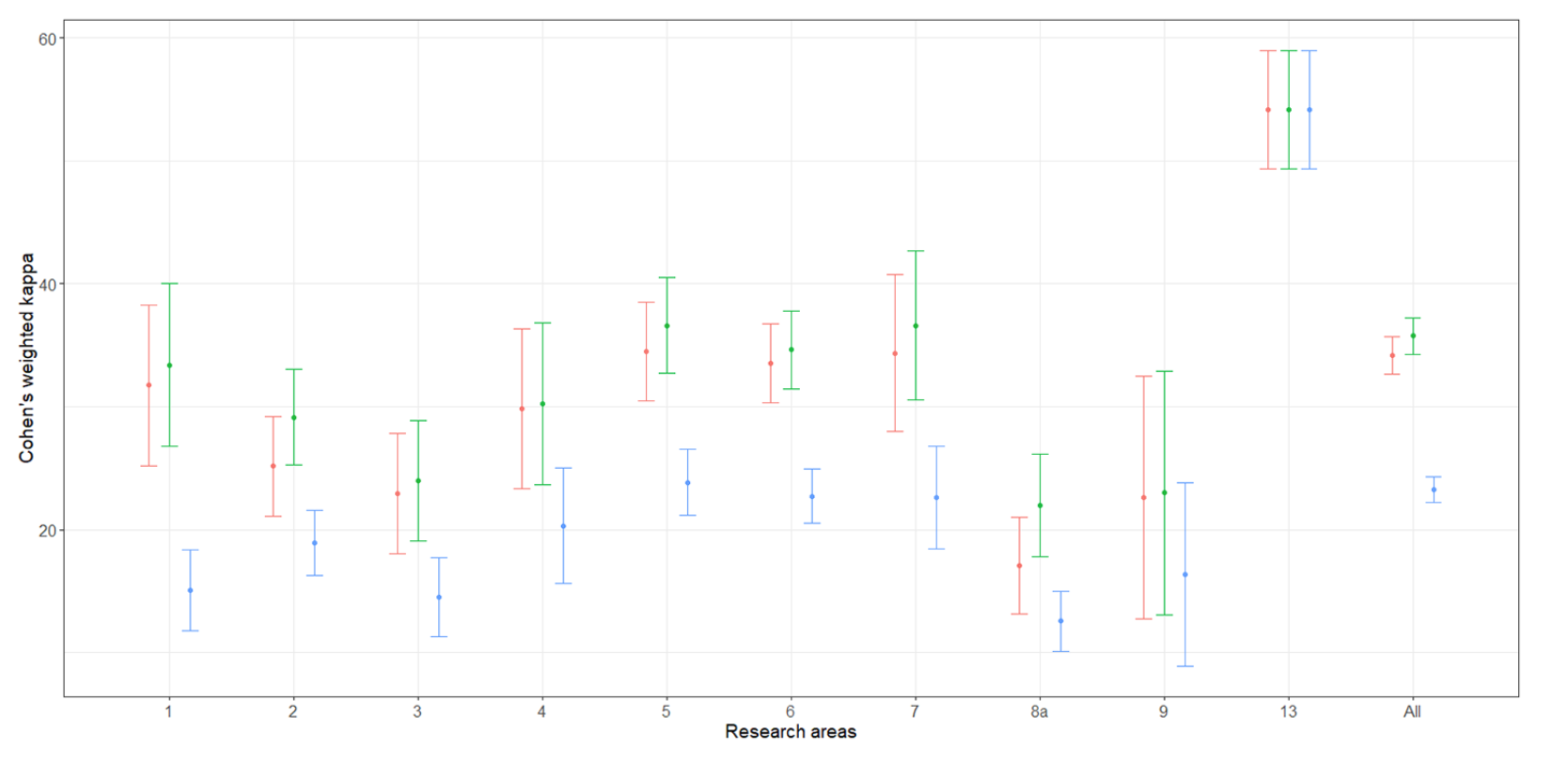
Figure 1. “Error-bar” plots of the Cohen’s kappa coefficient estimates (percent) for the first experiment: bibliometric vs peer review ratings. The confidence intervals are at 95% confidence level. The ANVUR estimates, properly corrected, are in red; alternative estimates are in green and blue. ANVUR estimate generates kappas higher than the blue alternative. Also, by considering the red estimates, the values of Cohen’s kappa are generally lower than 0.4 — low agreement— for all the research areas. The only exception was Area13 Economics and statistics for which the concordance is good. https://doi.org/10.1371/journal.pone.0242520.g003. List of scientific areas: Area 1: Mathematics and Informatics; Area 2: Physics; Area 3: Chemistry; Area 4; Earth Sciences; Area 5: Biology; Area 6: Medicine; Area 7: Agricultural and Veterinary Sciences; Area 8a: Civil Engineering; Area 9: Industrial and Information Engineering; Area 13: Economics and Statistics.
It is worthwhile to note that the systems of weights for calculating Cohen’s kappa developed by ANVUR tended to boost the value of the agreement with respect to other, more usual, weights. Hence, in both experiments the “real” level of concordance between bibliometrics and peer review is likely to be worse than the ones reported in the figures.
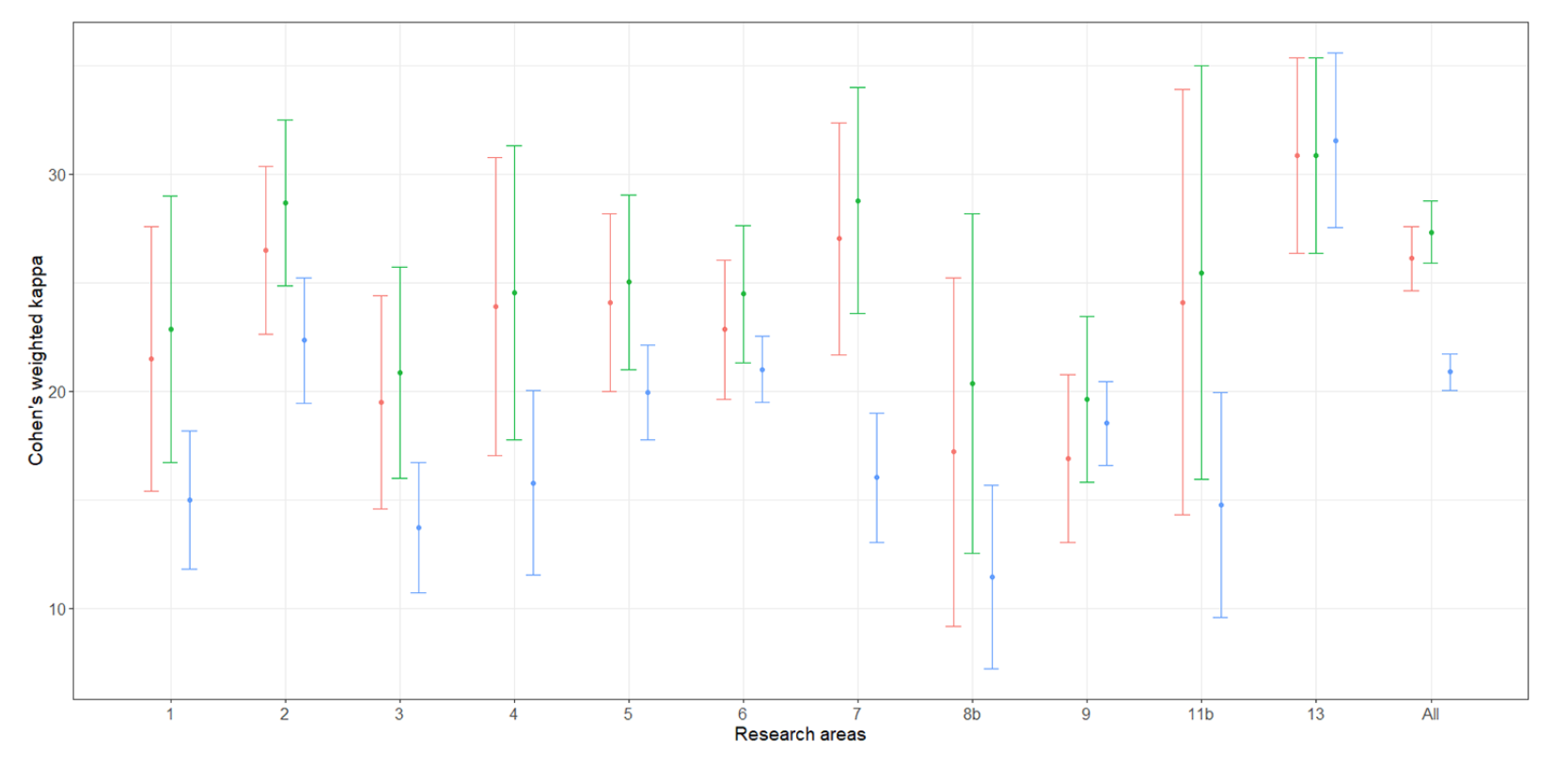
Figure 2. “Error-bar” plots of the Cohen’s kappa coefficient estimates (percent) for the second experiment: bibliometric vs peer review ratings. The confidence intervals are at 95% confidence level. The ANVUR estimates, properly corrected, are in red; alternative estimates are in green and blue. ANVUR estimate generates kappas higher than the blue alternative. Also, by considering the red estimates, the values of Cohen’s kappa are generally lower than 0.3 — low agreement—for all the research areas. Economics and statistics (Area 13) is similar to all the other areas. https://doi.org/10.1371/journal.pone.0242520.g004. List of scientific areas: Area 1: Mathematics and Informatics; Area 2: Physics; Area 3: Chemistry; Area 4; Earth Sciences; Area 5: Biology; Area 6: Medicine; Area 7: Agricultural and Veterinary Sciences; Area 8b: Civil Engineering; Area 9: Industrial and Information Engineering; Area 11b – Psychology; Area 13: Economics and Statistics.
The only exception to the weak concordance apparently happened in the first experiment for the field of Economics and Statistics, where the concordance is good. We have already discussed this result here. Now, by using the raw data, we show that the anomalous high concordance for economics and statistics in the first experiment was due to the modifications of the experimental protocol that occurred in this field. In a nutshell, for economics and statistics, a group of scholars was called to develop a bibliometric ranking of journals for attributing a bibliometric score to articles published in these journals. This same group of scholars was called also to manage peer reviews for the papers published in these journals. Finally, they formed the so-called “consensus groups” for deciding the final scores of articles after having received the referee reports.
Given all these conditions, it is hardly surprising that in economics and statistics the agreement between bibliometric and peer review reached a level not recorded in any other area considered in the Italian experiment. In sum, the concordance between bibliometrics and peer review in economics and statistics in the first experiment appear to be an artifact of the protocol of the experiment adopted by the panel. Indeed, in the second experiment, when an identical protocol was adopted for all the research areas, the agreement for economics and statistics was only weak and comparable with the other areas.
Lessons from the study
In sum, the two Italian experiments give concordant evidence that bibliometrics and peer review have less than weak level of agreement at an individual article level. This result is consistent with the ones reached for the REF by the Metric Tide report.
From the evidence presented in this paper, it is possible to draw a couple of research policy considerations. The first deals with the Italian research assessments exercises. The results of the experiments cannot be considered at all as validating the use of the dual method of evaluation adopted by ANVUR. At the current state of knowledge, it cannot be excluded that the use of the dual method introduced biases in the results of the assessments. Indeed, peer reviewers attributed scores to research products lower than bibliometrics. Hence the proportion of research outputs evaluated by the two different techniques might affect the aggregate results for research fields, departments, and universities: the higher the proportion of research outputs evaluated by peer review, the lower the aggregate score. Figure 3 documents that the average score at the research area level has — rather generally — a negative association with the percentage of papers evaluated by peer review. Consequently, it is questionable the use of the research assessment results for policy purposes and funding distribution since it depends not on research quality but on the method used for evaluation.
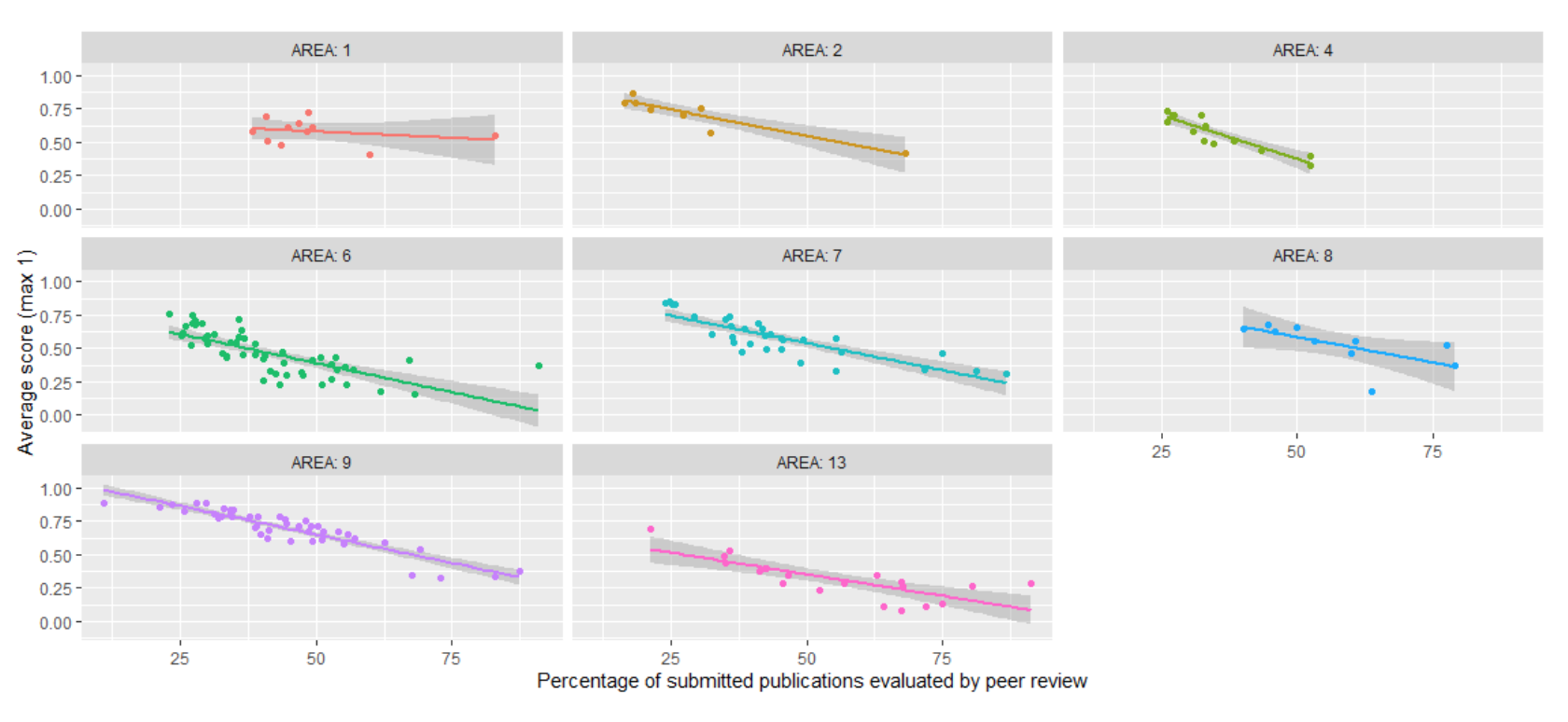
Figure 3. Average evaluation score and percentage of articles evaluated by peer review in the first research assessment exercise. Each point represents the average score for a research subfield of the considered area. Results https://doi.org/10.1371/journa…
The second and more general lesson from the two Italian experiments is that the use of a dual method of evaluation in a research assessment exercise should be done with extreme caution. A low agreement between bibliometrics and peer review at the level of individual article indicates that metrics should not replace peer review at the level of individual article. The use of the dual methods for reducing costs of evaluation might dramatically worsen the quality of information obtained in a research assessment exercise compared to the adoption of peer review only or bibliometrics only. A final note about research assessment is straightforward. The growing adoption of research assessments as tools for distributing public research funds started many years ago. Since then, no evidence has been produced showing that the benefits are higher than the cost of national assessment. We hope that the growing evidence about the distortion that massive research evaluation induces on researchers’ behavior (see e.g., “How Performance Evaluation Metrics Corrupt Researchers”) suggests a general reflection about its social desirability.
- 1. Baccini, A., Barabesi, L., & De Nicolao, G. (2020). On the agreement between bibliometrics and peer review: Evidence from the Italian research assessment exercises. PLOS ONE, 15(11), e0242520. doi:10.1371/journal.pone.0242520





